
2025 年的第一个全球范围的热搜:一个号称开源 Top 和与世界上最先进的闭源模型不分伯仲的中国 LLM。继
黑神话·悟空之后又一个让央妈报道的杭州科技公司。在整理最近学习的 AI 知识之前,先记录一下这个 AI 领域的大事件。
DeepSeek V3
基于 Transformer 架构,通过对架构、算法和数据的优化,在追求高性能的前提下,降低训练成本
主要设计
- 以 MLA(多头潜在注意力)进行推理,MoE(混合专家层)高效训练
- 通过无辅助损失策略实现负载均衡
- 多 token 预测训练目标,支持 FP8 混合精度训练
- 设计 DualPipe 算法,实现高效的流水线并行性,计算通信重叠以减少开销
- 开发跨节点全对全通信内核
训练流程
- 使用 14.8T 高质量、多样化的 token 预训练
- 上下文长度扩展,=> 32K, => 128K
- 通过监督微调 (SFT) 和强化学习 (RL)后训练 V3 基础模型
训练开销
训练资源:2048 个 H800 GPU 集群
时间成本
DeepSeek-V3 的完整训练成本: 278.8 万 GPU 小时
- 预训练阶段:2664K
- 上下文长度扩展:119K
- 后训练阶段:5K
经济成本
假设 H800 GPU 的租赁价格为每 GPU 小时 2 美元,总培训成本为 557.6 万美元
能力评估
- 教育类基准测试:优于所有开源模型,和闭源模型相当
- 事实性基准测试:
- SimpleQA 和中文 SimpleQA:优于所有开源模型,
- 英文 SimpleQA:落后于 GPT-4o 和 Claude-Sonnet-3.5
- 代码、数学和推理:在所有非长 CoT 开源和闭源模型中最佳
- 编码:最佳
- 工程相关:略低于 Claude-Sonnet-3.5,领先其他
架构
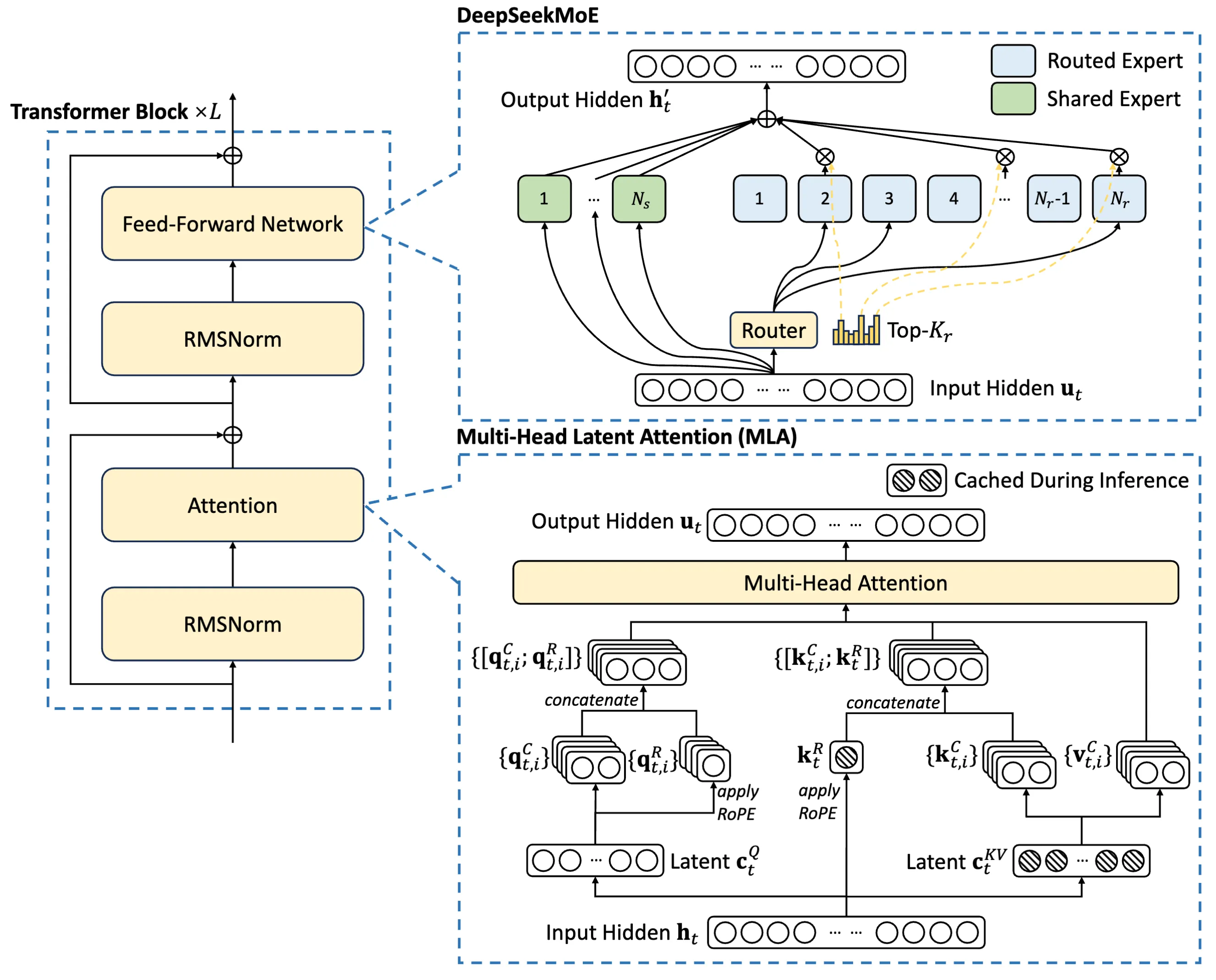
多头潜在注意力 (MLA):可实现高效推理
DeepSeekMoE:可实现经济训练